반응형
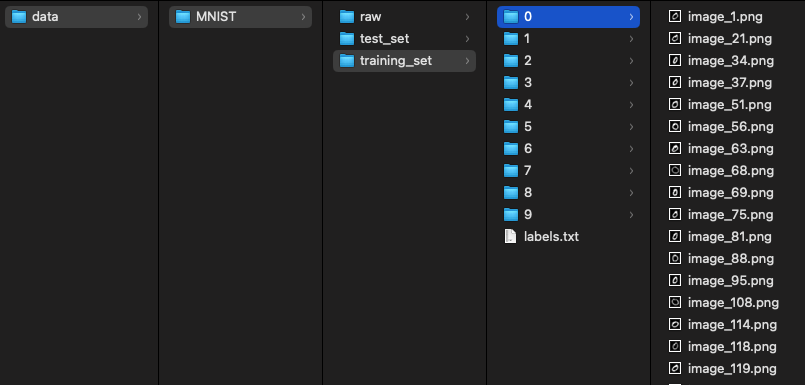
data/MNIST/row/ 폴더에 다운로드된 데이터셋 정보를 이용하여 image파일로 복원하고 해당 숫자(0-9)별로 폴더를 생성하고 각 숫자에 맞게 폴더내에 저장하도록 구현해 보았다.
labels.txt에는 각각의 이미지에대한 숫자 값을 기록하였다.
//
// MNIST 데이터셋을 이미지 파일로 복원
//
// Created by netcanis on 2023/07/20.
//
import matplotlib.pyplot as plt
import gzip
import numpy as np
import os
# 파일 압축 해제 함수
def decompress_file(compressed_file, decompressed_file):
with gzip.open(compressed_file, 'rb') as f_in, open(decompressed_file, 'wb') as f_out:
f_out.write(f_in.read())
'''
================= training_set =================
'''
# 이미지 개수 및 크기 추출
training_num_images = 60000 # 예시로는 60,000개의 이미지가 있는 것으로 가정
image_size = 28 # 이미지 크기는 28x28 픽셀
# 압축 해제할 파일 경로 (training_set)
training_image_compressed_file = 'data/MNIST/raw/train-images-idx3-ubyte.gz'
training_label_compressed_file = 'data/MNIST/raw/train-labels-idx1-ubyte.gz'
# 압축 해제된 파일 경로 (training_set)
training_image_decompressed_file = 'data/MNIST/raw/train-images-idx3-ubyte'
training_label_decompressed_file = 'data/MNIST/raw/train-labels-idx1-ubyte'
# 이미지 저장 폴더 경로
training_set_folder = 'data/MNIST/training_set'
# 라벨 저장 파일 경로
training_label_file = 'data/MNIST/training_set/labels.txt'
# 이미지 파일 압축 해제 (training_set)
decompress_file(training_image_compressed_file, training_image_decompressed_file)
# 라벨 파일 압축 해제 (training_set)
decompress_file(training_label_compressed_file, training_label_decompressed_file)
# 이미지 저장 폴더 생성 (training_set)
if not os.path.exists(training_set_folder):
os.makedirs(training_set_folder)
# 라벨 데이터를 numpy 배열로 변환 (training_set)
with open(training_label_decompressed_file, 'rb') as f:
# 헤더 부분은 건너뛰기
f.read(8)
# 라벨 데이터 읽기
buf = f.read()
# 라벨 배열 형태로 변환 (training_set)
training_labels = np.frombuffer(buf, dtype=np.uint8)
# 라벨 저장 파일 열기 (training_set)
with open(training_label_file, 'w') as f:
# 이미지에 대한 라벨 값을 순차적으로 저장
for i in range(training_num_images):
image_path = f'{training_set_folder}/{training_labels[i]}/image_{i}.png' # 이미지 파일 경로 (image_{i:05}.png)
label_value = training_labels[i] # 라벨 값
# 이미지 파일 경로와 라벨 값을 파일에 저장
f.write(f'{image_path}\t{label_value}\n')
# 이미지 데이터를 numpy 배열로 변환 (training_set)
with open(training_image_decompressed_file, 'rb') as f:
# 헤더 부분은 건너뛰기
f.read(16)
# 이미지 데이터 읽기
buf = f.read()
# 이미지 배열 형태로 변환
training_images = np.frombuffer(buf, dtype=np.uint8).reshape(training_num_images, image_size, image_size)
# 이미지를 순서대로 저장 (training_set)
for i, image in enumerate(training_images):
label_value = training_labels[i] # 라벨 값
# 해당 숫자의 폴더 생성
digit_folder = os.path.join(training_set_folder, str(label_value))
if not os.path.exists(digit_folder):
os.makedirs(digit_folder)
# 이미지 파일 경로
image_path = os.path.join(digit_folder, f'image_{i}.png')
plt.imsave(image_path, image, cmap='gray')
'''
================= test_set =================
'''
# 이미지 개수 및 크기 추출
test_num_images = 10000 # 예시로는 60,000개의 이미지가 있는 것으로 가정
test_image_size = 28 # 이미지 크기는 28x28 픽셀
# 이미지 저장 폴더 경로
test_set_folder = 'data/MNIST/test_set'
# 라벨 저장 파일 경로
test_label_file = 'data/MNIST/test_set/labels.txt'
# 압축 해제할 파일 경로 (test_set)
test_image_compressed_file = 'data/MNIST/raw/t10k-images-idx3-ubyte.gz'
test_label_compressed_file = 'data/MNIST/raw/t10k-labels-idx1-ubyte.gz'
# 압축 해제된 파일 경로 (test_set)
test_image_decompressed_file = 'data/MNIST/raw/t10k-images-idx3-ubyte'
test_label_decompressed_file = 'data/MNIST/raw/t10k-labels-idx1-ubyte'
# 이미지 파일 압축 해제 (test_set)
decompress_file(test_image_compressed_file, test_image_decompressed_file)
# 라벨 파일 압축 해제 (test_set)
decompress_file(test_label_compressed_file, test_label_decompressed_file)
# 이미지 저장 폴더 생성 (test_set)
if not os.path.exists(test_set_folder):
os.makedirs(test_set_folder)
# 라벨 데이터를 numpy 배열로 변환 (test_set)
with open(test_label_decompressed_file, 'rb') as f:
# 헤더 부분은 건너뛰기
f.read(8)
# 라벨 데이터 읽기
buf = f.read()
# 라벨 배열 형태로 변환 (test_set)
test_labels = np.frombuffer(buf, dtype=np.uint8)
# 라벨 저장 파일 열기 (test_set)
with open(test_label_file, 'w') as f:
# 이미지에 대한 라벨 값을 순차적으로 저장
for i in range(test_num_images):
image_path = f'{test_set_folder}/{test_labels[i]}/image_{i}.png' # 이미지 파일 경로 (image_{i:05}.png)
label_value = test_labels[i] # 라벨 값
# 이미지 파일 경로와 라벨 값을 파일에 저장
f.write(f'{image_path}\t{label_value}\n')
# 이미지 데이터를 numpy 배열로 변환 (test_set)
with open(test_image_decompressed_file, 'rb') as f:
# 헤더 부분은 건너뛰기
f.read(16)
# 이미지 데이터 읽기
buf = f.read()
# 이미지 배열 형태로 변환
test_images = np.frombuffer(buf, dtype=np.uint8).reshape(test_num_images, image_size, image_size)
# 이미지를 순서대로 저장 (test_set)
for i, image in enumerate(test_images):
label_value = test_labels[i] # 라벨 값
# 해당 숫자의 폴더 생성
digit_folder = os.path.join(test_set_folder, str(label_value))
if not os.path.exists(digit_folder):
os.makedirs(digit_folder)
# 이미지 파일 경로
image_path = os.path.join(digit_folder, f'image_{i}.png')
plt.imsave(image_path, image, cmap='gray')
실행 결과는 다음과 같다.
2023.07.19 - [AI] - MNIST 데이터셋 다운로드
2023.07.19 - [AI] - MNIST 데이터셋을 이미지 파일로 복원
2023.07.19 - [AI] - MNIST 데이터셋 로더
2023.07.19 - [AI] - MNIST 모델 테스터
2023.07.19 - [AI] - MINST - SVC(Support Vector Classifier)
2023.07.19 - [AI] - MNIST - RandomForestClassifier
2023.07.19 - [AI] - MNIST - Keras
2023.07.19 - [AI] - MNIST - TensorFlowLite
반응형
'개발 > AI,ML,ALGORITHM' 카테고리의 다른 글
| MNIST 모델 테스터 (0) | 2023.07.19 |
|---|---|
| MNIST 데이터셋 로더 (0) | 2023.07.19 |
| MNIST 데이터셋 다운로드 (0) | 2023.07.19 |
| Neural Network (XOR) (0) | 2022.11.18 |
| 2D 충돌처리 (0) | 2020.12.12 |

SKY STORY