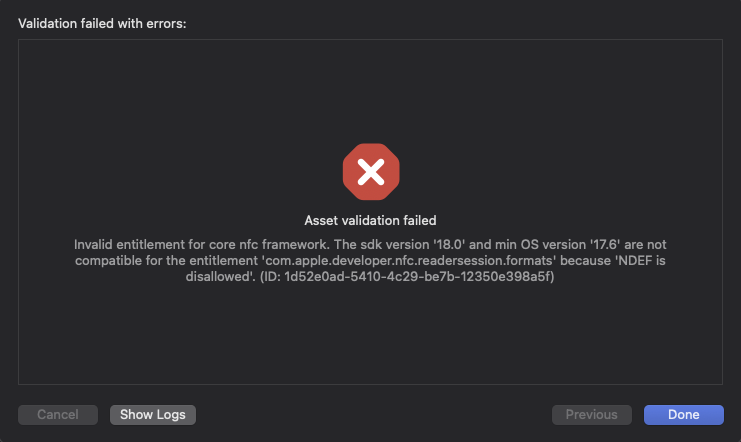
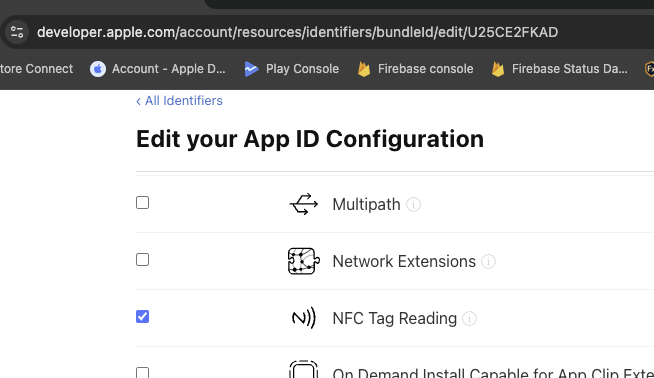
반응형
Android Studio 앱서명 설정
Android Studio 열기: 프로젝트를 열고, 메뉴 바에서 Build → Generate Signed Bundle / APK...를 클릭.
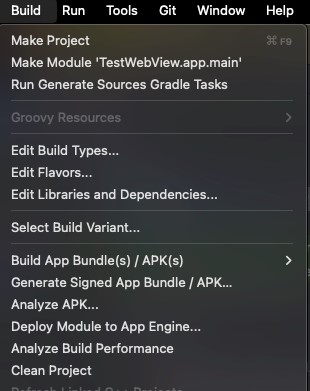
Signed Bundle or APK 선택:
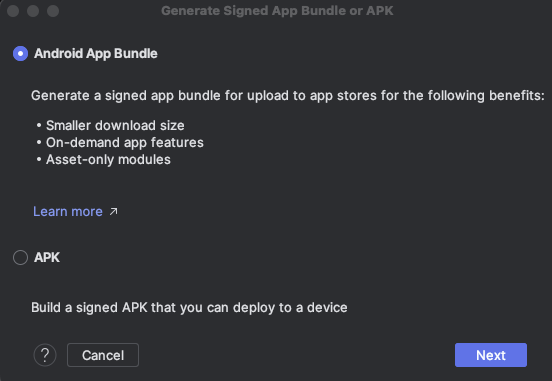
- Android App Bundle(권장) 또는 APK 중 하나를 선택한다. Google Play 배포 시에는 App Bundle을 선택하는 것이 좋다.
- APK로 수동으로 배포할 경우에는 APK를 선택할 수 있다.
키스토어 설정 화면:
- **Create new...**을 클릭하여 새 키스토어 파일을 생성.
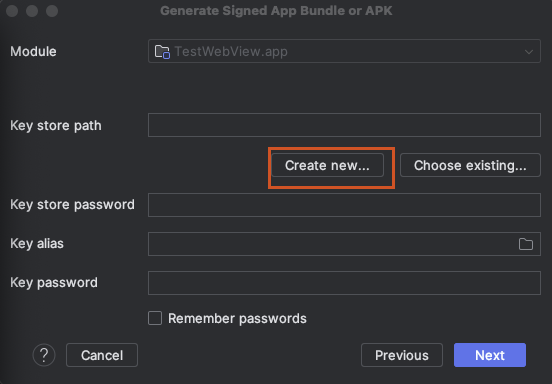
키스토어 파일 경로 설정:
- /app폴더 아래 keystore폴더 생성후 읽기/쓰기 권한 설정)
- Key store path: 키스토어 파일을 저장할 위치 지정.
ex) /Users/netcanis/projects4/TestWebview/app/keystore/testwebview-release-key.jks - Password : keystone 비번입력.
- Alias : alias별칭을 입력. ex) testwebview-release-key-alias
- Password : alias 비번 입력.
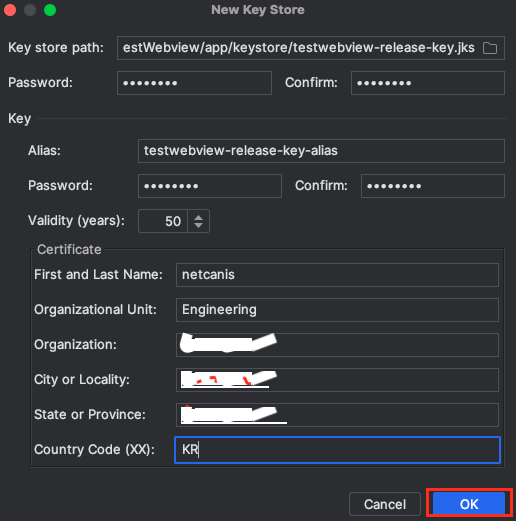
사용자 정보 입력:
- First and Last Name: 개발자 이름을 입력.
- Organization Unit: 부서 또는 팀 이름을 입력. (예: Engineering)
- Organization: 회사 이름을 입력.
- City or Locality: 도시 이름을 입력.
- State or Province: 주 또는 도 이름을 입력.
- Country Code (XX): 두 자리 국가 코드를 입력. (예: KR)
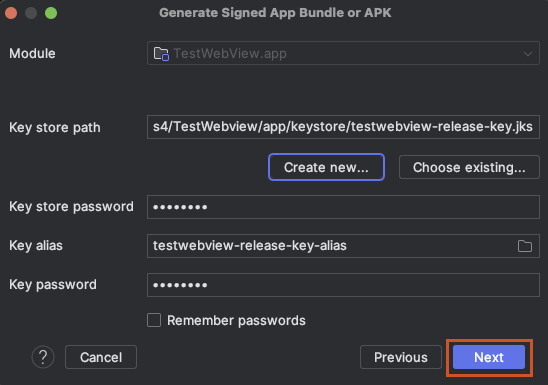
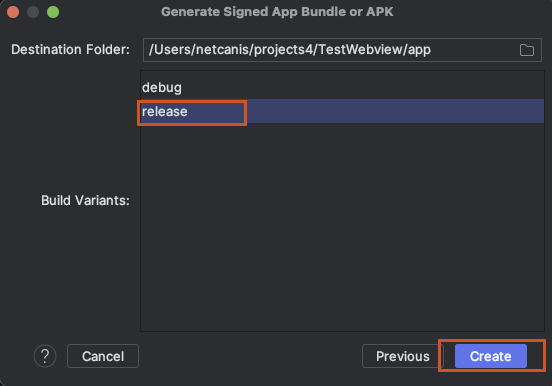
Release를 선택하고 Create 버튼 클릭
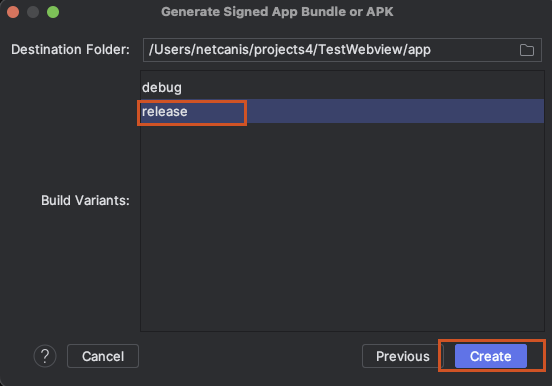
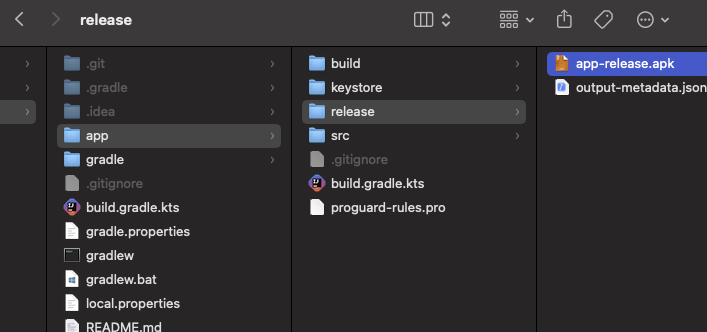
생성된 keystore 파일 확인
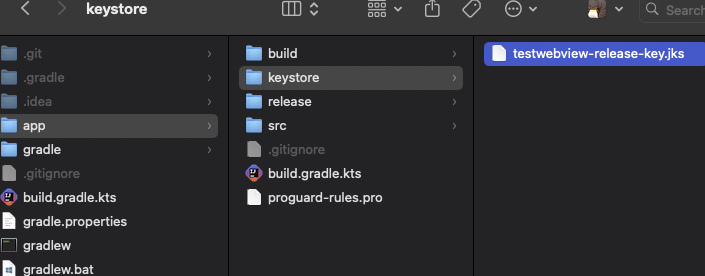
서명된 APK파일 생성
Android Studio 열기: 프로젝트를 열고, 메뉴 바에서 Build → Generate Signed Bundle / APK...를 클릭
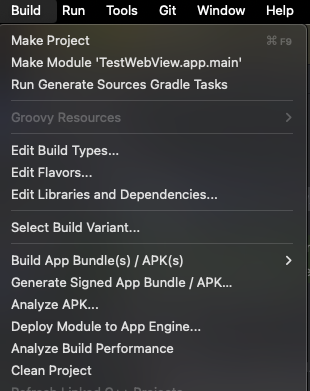
APK 선택
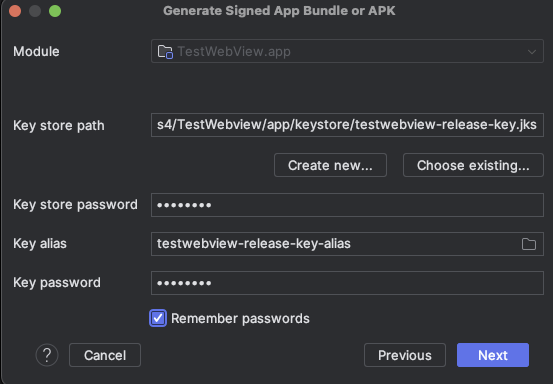
keystore 비밀번호 및 Key alias 비밀번호를 입력
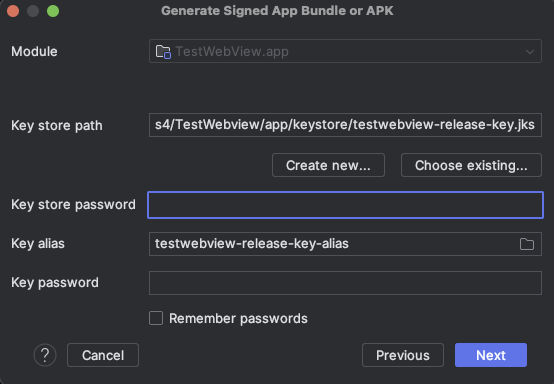
‘Remember passwords’ 체크하고 ‘Next’버튼 클릭
Release를 선택하고 Create 버튼 클릭
생성된 APK파일 확인
반응형
'개발 > Android' 카테고리의 다른 글
| 디버그 서명 인증서와 릴리즈 서명 인증서 차이 (0) | 2024.10.14 |
|---|---|
| Android앱에 Firebase 추가시 디버그 서명 인증서 SHA-1 등록 (0) | 2024.10.14 |
| AGP 8.0 이상에서 주목해야 할 주요 변경 사항 (0) | 2024.10.10 |
| Android 13(QPR) 및 14(API 34)에서 적용된 새로운 보안 정책 및 기능 변경과 주의 사항 (0) | 2024.10.04 |
| Gradle 8.0 이상 주요 변경사항 (1) | 2024.10.04 |

SKY STORY